5. Типовые конфигурации отказоустойчивого кластера и покрываемые ими угрозы
5.1. Общий вид кластера и его составляющие
5.1.1. Кластер Cook
Типичное решение с кластером под управлением cook содержит следующие элементы:
Типичными клиентами кластера будут:
Приложение использующее ресурсы кластера
Cook и РБД в данном случае составляют неделимый сервис, так как cook управляет конфигурацией и процессами РБД.
Consul формирует собственный кластер предоставляет cook K/V-хранилище для хранения конфигурации и функционал распределенных блокировок.
Дисковый ресурс используется для передачи логов репликации между узлами.
Приложение может использовать API Consul, API Cook или прокси-сервер (HAProxy, gobetween) для подключения к кластеру РБД.
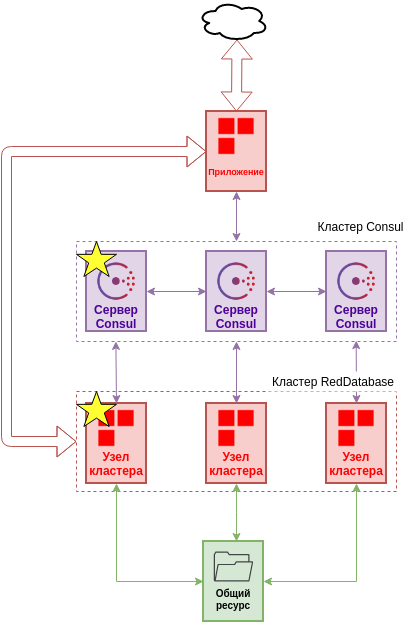
Схематический вид кластера RedDatabase
В общем случае отказоустойчивый кластер решает проблему единой точки отказа, но необходимо принимать во внимание инфраструктурные особенности конкретных конфигураций.
Для поддержания безостановочной работы кластера нужно обеспечить в частности:
Кворум кластера Consul
Связность сети между cook и Consul
Работу общего дискового ресурса
Связность сети между cook и дисковым ресурсом
5.1.2. Узел Cook
Узел Cook или узел кластера RedDatabase - обособленная машина, на которой располагаются:
Оркестратор Cook
RedDatabase Enterprise Edition
Файл базы данных
Клиент Consul
Подключение к общему ресурсу
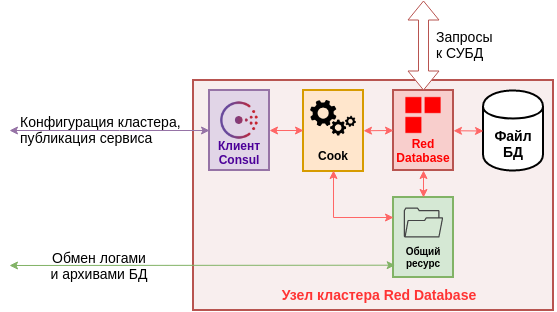
Схематический вид узла кластера RedDatabase
Конфигурация Cook может выглядеть следующим образом:
Windows 10/Server 2019 и выше или RedOS 7.2/RHEL 7/CentOS 7/Oracle Linux 7 и выше
Если в качестве общего ресурса используется CIFS, то диски должны быть смонтированы в режиме WRITETHROUGH
Хранилище достаточное для постоянного хранения файла базы данных
Хранилище достаточное для временного хранения архивов базы данных (в зависимости от настроек репликации Cook)
5.1.3. Узел Consul
Обычно выделяют серверные и клиентские узлы Consul. Серверные выполняют работу поддержания кворума, репликации хранилища, связи LAN/WAN между узлами и прочее. Легковесные клиентские предоставляют доступ к API и не участвуют в кворуме. Количество узлов кластера определяется требуемой избыточностью для кворума по формуле (N/3)+1, где N - количество серверных узлов. Так, для 3 узлов кластера необходимо 2 работающих узла для поддержания кворума. В общем случае узлы Consul - отдельные машины, но для упрощения вместо клиента на узле cook может находиться непосредственно серверный узел кластера Consul, при этом необходимо помнить, что при выводе из кластера этой машины кворум Consul может быть нарушен.
5.1.4. Узел приложения
Узел приложения может быть произвольным, быть настроенным как HA ресурс или отсутствовать вовсе. В простейшем случае, приложение, которое принимает клиентские запросы извне, выполняет подключение к кластеру RedDatabase через прокси, например gobetween.
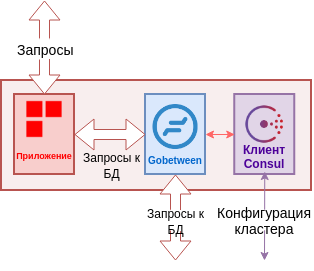
Схематический вид узла приложения
Подсказка
Примеры конфигураций с Gobetween и HAProxy (Использование реверсивных прокси)
Подсказка
Также возможно прямое подключение к кластеру, минуя прокси, но приложение при этом должно опросить Consul или узлы Cook, чтобы узнать текущий master.
5.2. Конфигурации кластера
5.2.1. Все узлы на одном сервере
Строго говоря, данный вариант не является отказоустойчивой конфигурацией и может использоваться только в качестве демонстрации или разработки. При сбое процесса Ред Базы или cook будет выполнено аварийное переключение.
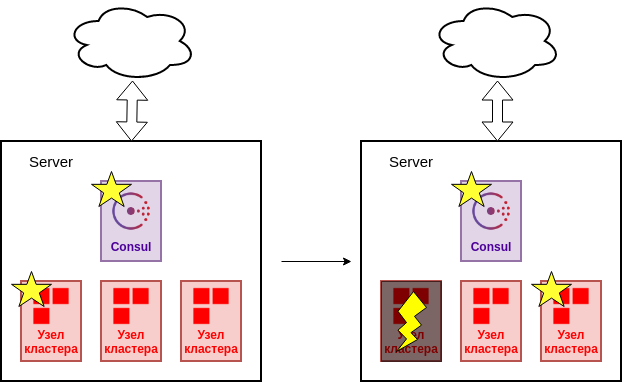
Сбой процесса
Но, очевидно, что сбой сервера приведет к полной потере кластера.
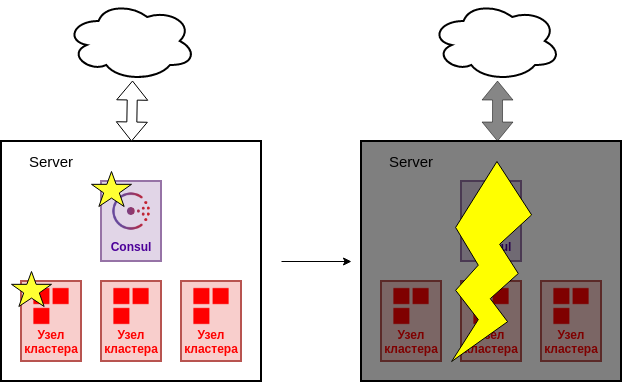
Сбой сервера
5.2.2. Узлы кластера в гипервизоре
Развертывание узлов на виртуальных машинах с одной стороны более удачный вариант, например для того, чтобы уменьшить время простоя при обновлениях.
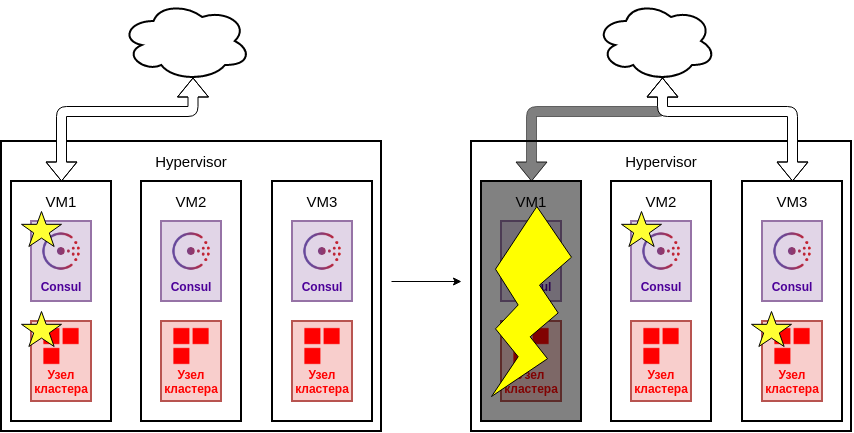
Сбой виртуальной машины
Однако, когда все машины кластера являются развернуты в одном гипервизоре, точкой отказа является сам гипервизор, так как при сбое весь кластер станет недоступен.
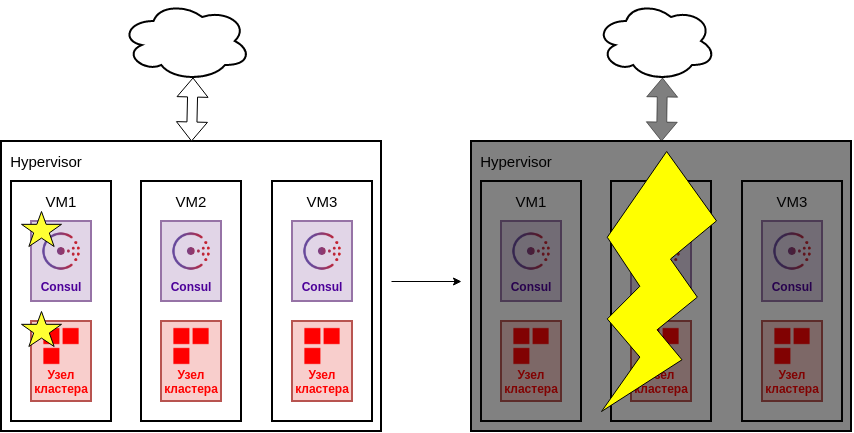
Сбой гипервизора
Логичным решением в данном случае избегать расположения узлов кластера на одном гипервизоре.
Также возможно применение средств отказоустойчивости самого гипервизора, но это выходит за рамки данного документа.
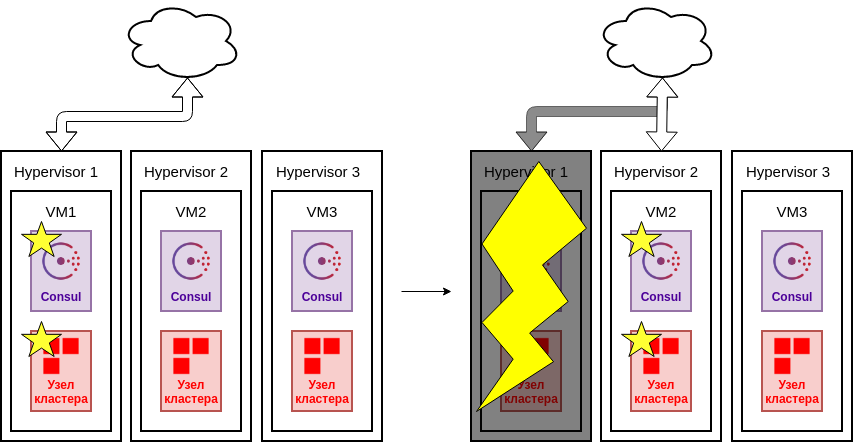
Сбой гипервизора
Необходимо также помнить про поддержку кворума кластера Consul. Если узлы кластера Consul находятся на тех же машинах, что и cook, то для поддержания кворума должно быть запущено достаточное их количество.
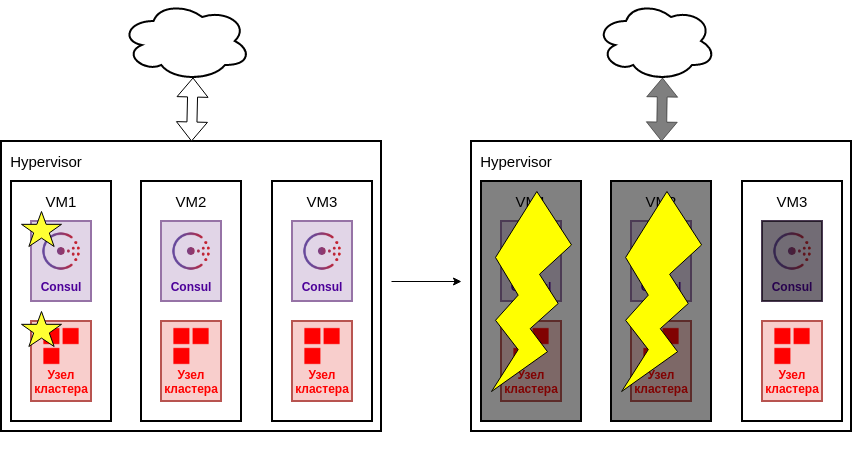
Потеря кворума Consul
5.2.3. Узлы кластера на резервных площадках
При возможном географическом разнесении кластера, например резервные узлы в разных ЦОД (Data Center, DC), становится возможным защитить кластер от выхода из строя всего ЦОД, но при этом остается проблема кворума Consul.

Выход из строя узла на одном из ЦОД

Выход из строя ЦОД. Потеря кворума Consul
Для поддержания кворума один из узлов Consul может быть свидетелем на отдельной площадке

Выход из строя ЦОД без потери кворума Consul
Предупреждение
Конфигурация с несколькими ЦОД в данный момент возможна только при наличии обмена между ними трафиком уровня 2 (L2)
5.2.4. Fencing
Конфигурация описана в разделе Fencing
При работе с данными в любой распределенной системе важна их консистентность. Когда один из узлов работает в режиме master он управляет как БД, так и текущим логом транзакций. В момент отказа этого master, мы должны быть уверены, что он изолирован и перестал выполнять любую работу с данными до того, как мы начали ввод в строй новый master. Проконтролировать это невозможно ни снаружи ни внутри, поэтому важно настроить аппаратный watchdog, который выключит узел физически, в аварийной ситуации.
Watchdog настраивается для каждого узла физической или виртуальной машины. После старта master watchdog начинает свою работу и ожидает, что его будут периодически «сбрасывать». Во время аварийной ситуации, узел пытается штатно завершить работу master, при этом watchdog перестает обновляться. В конечном счете, при хорошем исходе узел переходит в режим standalone и останавливает watchdog, но если узел не успевает корректно выполнить завершение работы, то это сделает watchdog аппаратно.
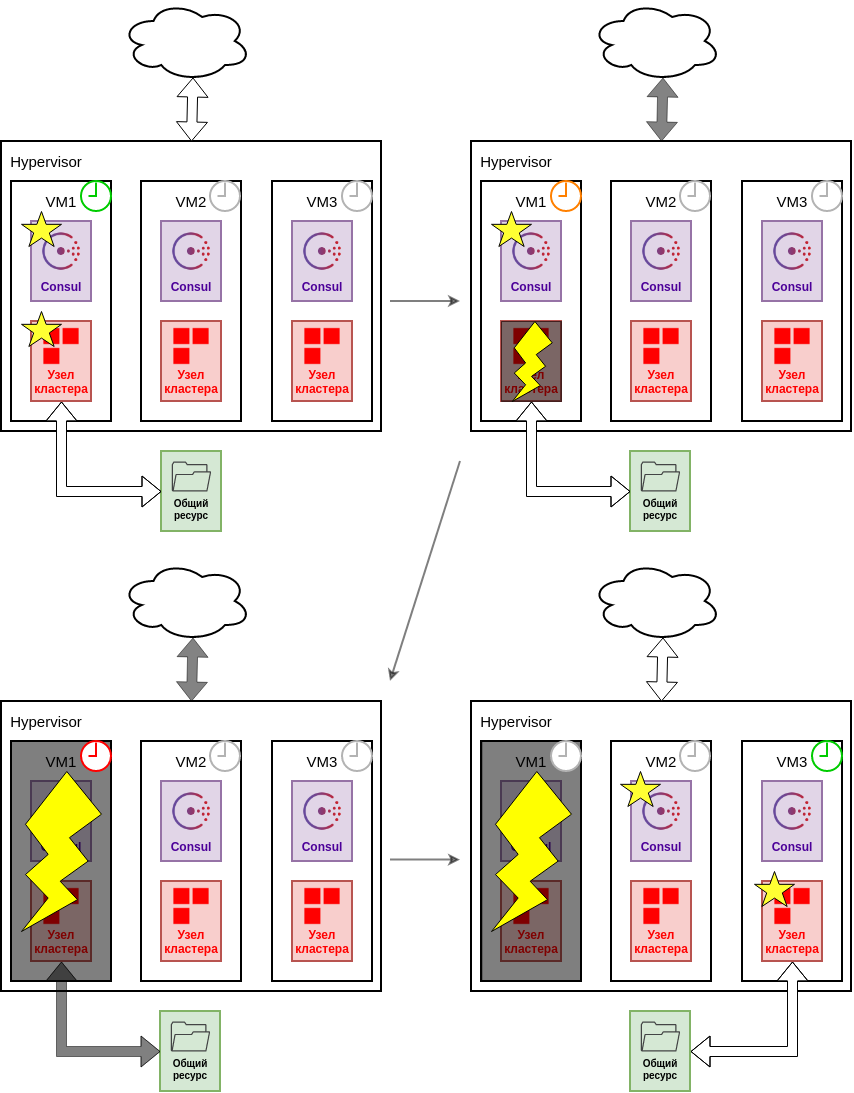
Работа watchdog во время изоляции узла
Ссылки