12. Репликация
12.1. Особенности репликации
Большая часть репликаторов, написанных для Firebird, представляет собой внешние по отношению к серверу приложения. Они хорошо подходят для миграции данных между различными базами данных или даже между различными СУБД, но плохо подходят для поддержания копии БД в рамках решения задачи создания отказоустойчивого кластера. Основной проблемой при этом является производительность, т.к. сторонние средства создают дополнительную нагрузку при синхронизации данных, причём она обычно избыточна и существенно замедляет работу СУБД. Кроме того, не все средства репликации могут гарантировать идентичность данных в основной базе и в копии при возникновении сбоя.
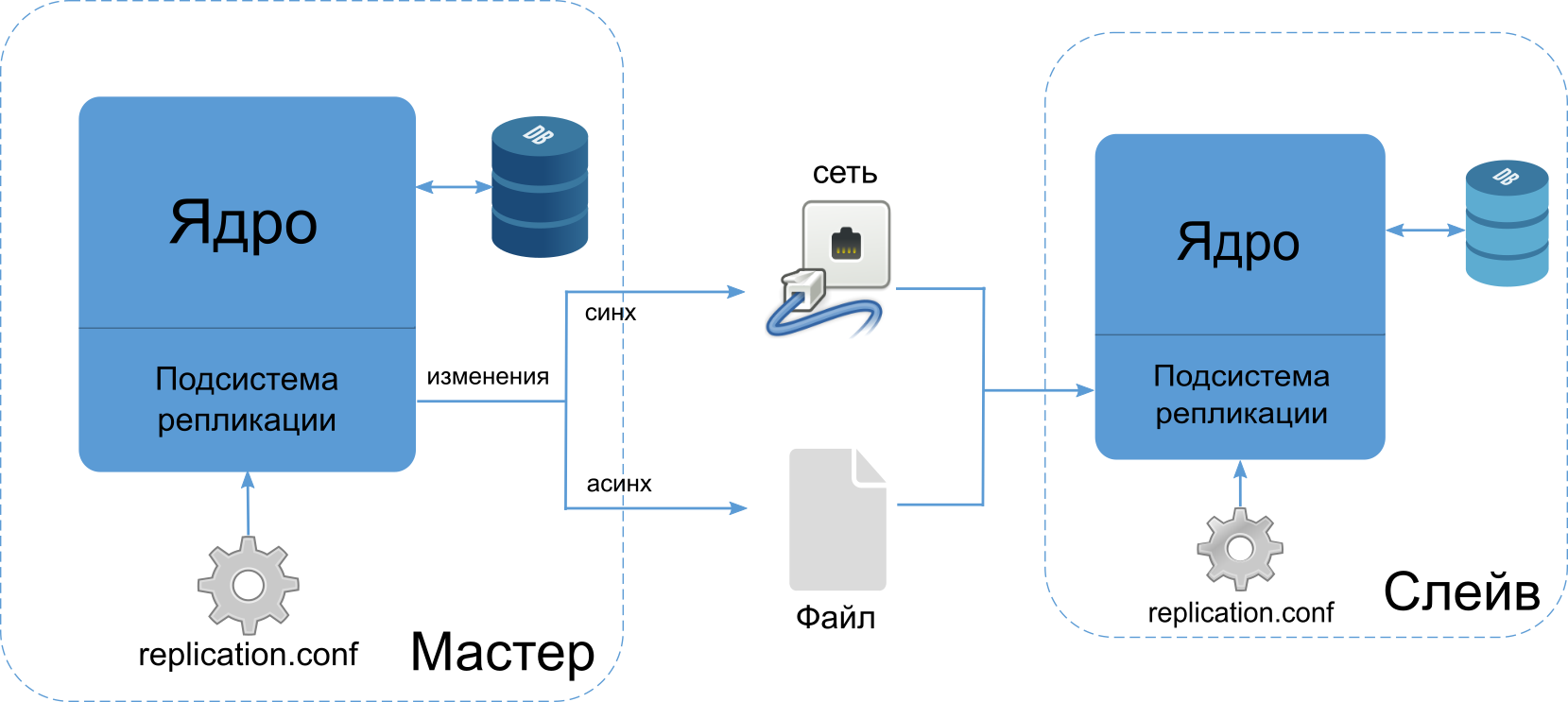
Встроенная репликация предназначена для обеспечения повышенной отказоустойчивости в случае повреждения физической структуры файла базы данных, вызванной техническим сбоем оборудования, программным сбоем операционной системы или самой СУБД. Она подразумевает перенос любых изменений данных с основного рабочего сервера на один или несколько резервных серверов, гарантируя, таким образом, их идентичность с точки зрения хранящихся на них данных. При этом главный сервер принято называть мастером, а резервные – слейвами.
Элемент репликации представляет собой запись в таблице, любые изменения которой передаются на резервные сервера. Также передаются и контекстные изменения, а именно соединения и транзакции, в которых происходит изменение записи. Таким образом, основными событиями репликации являются:
создание и завершение соединений;
начало, конец и откат каждой транзакции;
начало, конец и откат точки сохранения;
вставка, обновление и удаление записей;
изменение генераторов.
Однозначное соответствие строк на основном и резервном серверах определяется уникальным индексом. Механизм репликации не содержит каких-либо средств, гарантирующих логическую непротиворечивость данных между основной базой и её резервными копиями. Полноценно реплицируются только таблицы, содержащие уникальный индекс, например, первичный ключ. В случае отсутствия или неактивности такого индекса возможна репликация только операций вставки записи.
В процессе работы репликации возможны конфликты. Конфликтом считается обнаруженное несоответствие между данными на основном и резервном серверах. Примерами конфликтов являются:
наличие строки в реплике при попытке ее вставки;
отсутствие строки в реплике при ее изменении или удалении;
наличие транзакции при попытке её запуска;
отсутствие транзакции при её завершении.
Если произошел конфликт другого вида, это расценивается как ошибка репликации, которая приведёт либо к отключению репликации и продолжению работы мастера в штатном режиме, либо к отмене операции, во время которой произошла ошибка и сообщению о ней пользователю.
12.2. Режимы репликации
Существует два основных режима работы репликации: синхронный и асинхронный. В первом случае при наступлении события репликации в мастер-базе, оно должно быть также выполнено на всех слейв-базах для того, чтобы событие считалось завершенным. Логически это означает, что существует лишь одна версия данных. Основной недостаток синхронной репликации – она создаёт дополнительную задержку в работе мастера, т.к. СУБД должна дождаться ответа от реплики, чтобы считать операцию завершенной.
В случае асинхронной репликации обновления мастер-базы пишутся в журналы, которые распространяются на реплику спустя некоторое время, а не в той же транзакции. Таким образом, при асинхронной репликации уменьшаются простои мастера, но при этом вводится задержка, в течение которой реплики могут быть фактически неидентичными. Кроме того, больше вероятность конфликтов из-за того, что процесс копирования журналов репликации выполняется сторонними средствами.
Рассмотрим подробнее принципы работы и особенности разных режимов репликации.
12.2.1. Синхронная репликация
При синхронной репликации в процессе подключения к основному серверу проверяется наличие и доступность резервных серверов, после чего устанавливается с ними постоянное соединение. При ошибке подключения к слейву подключение к мастеру также завершается с ошибкой. Подключение к слейву может выполняться от имени текущего пользователя, либо от имени пользователя, заданного в конфигурации.
При наступлении событий в рамках транзакции, они записываются в буфер репликации, который передаётся на слейв либо при его заполнении, либо при наступлении определённых событий, например, коммита транзакции или завершения соединения. Слейв, получив репликационный пакет, должен выполнить все указанные в нём действия. При ошибке в любом из них применение пакета прекращается, а сообщение об ошибке репликации отправляется на мастер.
При синхронной репликации особую проблему составляет коммит транзакции. При наличии сложной отложенной работы время коммита может существенно увеличиться, если он будет последовательно выполняться на мастере и на слейве. Поэтому при репликации коммита на слейв посылается специальное событие подготовки коммита, и отложенная работа на мастере и слейве выполняется параллельно.
12.2.2. Асинхронная репликация
Асинхронная репликация также использует буферизацию событий репликации, но не посылает содержимое буфера на слейв, а пишет его в журнал репликации. Он представляет собой набор бинарных файлов (сегментов журнала) фиксированного размера, хранящихся в директории, заданной в конфигурации репликации. СУБД сбрасывает буферы с событиями репликации в текущий (активный) сегмент до тех пор, пока он не будет заполнен. После этого отдельный поток выполняет архивацию сегмента с помощью внешней команды. По окончании архивации сегмент считается свободным и может снова использоваться для записи событий репликации.
В данной модели существует четыре возможных состояния сегментов журнала:
USED– сегмент в данный момент используется. В конкретный момент времени он единственный. Когда сегмент достигает заданного размера, он считается заполненным и запись в него прекращается. То же самое происходит при простое сегмента в течении минуты.FULL– сегмент заполнен и ждет архивации. Ей занимается отдельный поток, который оповещается с помощью семафора. Также возможна ручная архивация с помощью утилитыrdblogmgr.ARCH– сегмент в процессе архивации.FREE– помечается после архивации, как возможный к использованию. Как только сегментUSEDпереходит в состояниеFULL, ищутся сегменты в состоянииFREE, чтобы использовать их снова. Если такие не найдены, создается новый.
Cегменты журнала могут быть применены вручную утилитой rdblogmgr.
Каждый сегмент имеет уникальный номер, который генерируется последовательно. Этот номер в сочетании с UUID базы данных обеспечивает глобальную уникальную идентификацию сегментов журнала. Глобальный счетчик последовательности хранится в реплицированной базе данных и никогда не сбрасывается (пока база данных не будет восстановлена из резервной копии).
Сегменты регулярно ротируются. Этот процесс контролируется либо максимальным размером сегмента, либо таймаутом, оба порога настраиваются. Как только активный сегмент достигает порогового значения, он помечается как «полный», и запись переключается на следующий доступный сегмент. Полные сегменты архивируются и затем повторно используются для последующих записей. Архивирование в основном означает копирование сегмента с целью передачи его на хост реплики и применения там. Копирование может быть выполнено самим сервером РЕД Базы Данных или, альтернативно, указанной пользователем командой.
Со стороны реплики сегменты журнала применяются в порядке
последовательности репликации. Сервер РЕД Базы Данных периодически
сканирует новые сегменты, появляющиеся в настроенном каталоге. Как
только следующий сегмент найден, он реплицируется. Состояние репликации
хранится в локальном файле с именем {UUID} (для каждого источника репликации) и
содержит следующие маркеры: последняя последовательность сегментов
(LSS), самая старая последовательность сегментов (OSS) и список активных
транзакций, запущенных между OSS и LSS. LSS означает последний
реплицированный сегмент. OSS означает сегмент, который начал самую
раннюю транзакцию, которая не была завершена во время обработки LSS. Эти
маркеры управляют двумя вещами: какой сегмент должен быть реплицирован
следующим и когда файлы сегмента можно безопасно удалить. Сегменты с
номерами между OSS и LSS сохраняются для воспроизведения журнала после
отключения репликатора от базы данных реплики (например, из-за ошибки
репликации или времени простоя). Если нет ожидающих активных транзакций
и LSS был обработан без ошибок, все сегменты включая LSS удаляются. В
случае любой критической ошибки репликация временно приостанавливается и
повторяется после истечения времени ожидания.
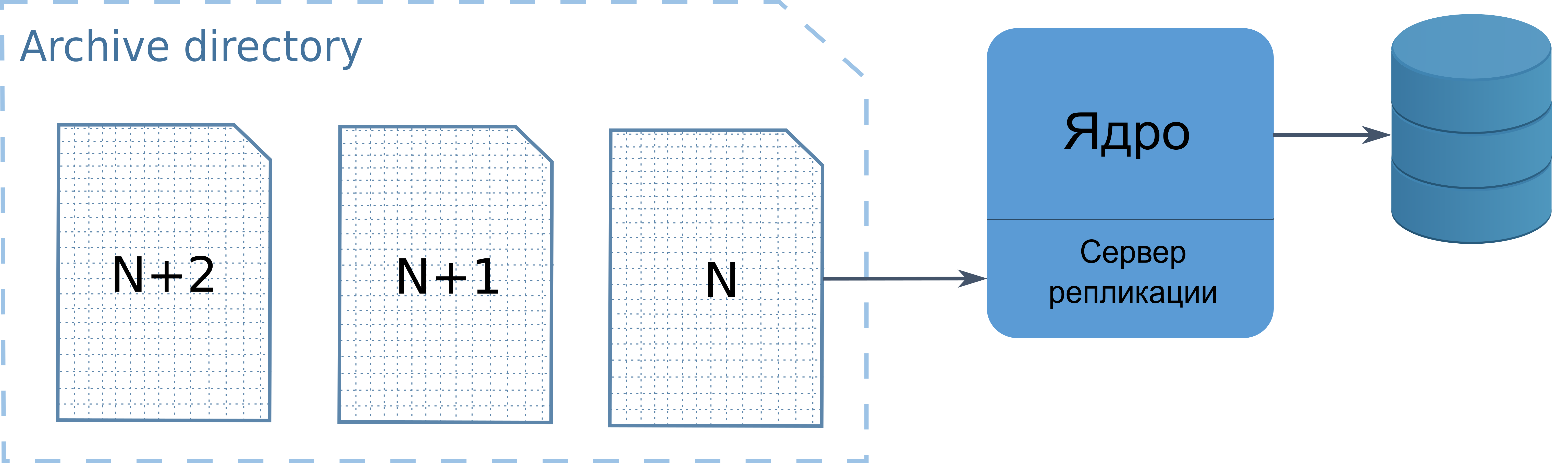
Применение журнала к реплике выполняется сервером репликации. В случае
Суперсервера или Суперклассика, это отдельный поток в запущенной СУБД.
Он читает архивные сегменты из указанного каталога и применяет их к БД.
Если в системе установлен и работает классик, то сервер репликации
запускается отдельным процессом суперклассика с ключом -R.
12.2.3. Адаптивная репликация
Примечание
Адаптивная репликация доступна только в промышленной редакции. Подробнее различия функционала редакций описаны в разделе Редакции СУБД РЕД База Данных 5.
Адаптивная репликация объединяет в себе два описанных выше режима. Основным преимуществом этого режима является то, что мастер-база остаётся доступной на протяжении всего процесса репликации.
При старте репликации начинается ведение журнала репликации, таким образом выполняется асинхронная репликация. Если со слейв-базой возможно установить соединение и данные на ней актуальны, то включается ещё и синхронная репликация. Если соединение со слейв-базой потеряно, то данные перестают реплицироваться синхронно. Есть возможность возобновить синхронную репликацию, применив накопившиеся асинхронные журналы к слейв-базе, когда она станет доступна.
Примечание
Если используется архитектура Classic, то для восстановления синхронной репликации необходимо снять всю нагрузку на базу данных.
Возобновить нагрузку можно после синхронизации узлов.
Для возобновления синхронной репликации необходимо, чтобы данные на слейве были актуальны.
Проверка актуальности данных производится при попытке отправить синхронный репликационный пакет.
Если разрыв между мастером и слейвом достигает количества журналов,
которое меньше или равно backoff_lag, то плагин репликации запустит механизм восстановления синхронизации.
Плагин репликации будет замедлять процесс коммита в мастере на initial_backoff_delay миллисекунд.
Если журналы применились, но данные на слейве всё ещё не актуальны, то задержка будет увеличена в backoff_factor раз.
Так с каждой попыткой синхронизации время задержки будет расти в backoff_factor раз до достижения max_backoff_delay.
Задержка будет выполняться, пока данные на слейве не станут актуальными.
или пока разница в журналах между мастером и репликой не превысит backoff_lag.
12.3. Отчет об ошибках
Все ошибки и предупреждения репликации (например, обнаруженные конфликты) записываются
в файл replication.log, хранящийся в корневом каталоге установки РЕД Базы Данных. Этот
файл также может содержать подробное описание операций, выполняемых репликатором.
12.4. Настройка системы репликации
12.4.1. Файл конфигурации
Для настройки системы репликации используется файл replication.conf, находящийся в
корневом каталоге СУБД. Файл настраивается как на стороне мастер
сервера, так и на стороне слейва. Все параметры настройки содержатся в
блоке database{ ... }, и по умолчанию закомментированы. Настройки можно проводить
глобально сразу для всех баз данных и отдельно для каждой базы данных.
Примечание
database должен быть
указан полный путь к базе данных. Псевдонимы и подстановочные знаки не
принимаются.database = /your/db.fdb { ... }
Первое слово в строке внутри блока, начинающейся не с символа комментария, считается названием параметра. Справа от имени параметра, после символа равенства, указывается значение параметра.
Параметры настройки на мастере
- plugin
Плагин, используемый для репликации. По умолчанию используется встроенная репликация.
plugin =
- buffer_size
Указывает размер буфера операций на мастер-базе, при достижении которого он будет отправлен на слейв-базы или записан в журнал. Этот параметр не влияет на такие операции, как
commitилиrollback; при выполнении этих операций буфер отправляется немедленно и ожидается подтверждение от всех удачного исполнения.buffer_size = 1048576 # 1MB
- include_filter
Строковый параметр в формате регулярного выражения в синтаксисе SQL, который задает, какие таблицы базы данных необходимо включить в репликацию. По умолчанию реплицируются все таблицы. Любая таблица, которая должна быть реплицирована, должна иметь первичный ключ или, по крайней мере, уникальный ключ.
include_filter = (W$|ORD$)%
- exclude_filter
Строковый параметр в формате регулярного выражения в синтаксисе SQL, который задает, какие таблицы базы данных необходимо исключить из репликации. По умолчанию реплицируются все таблицы. Любая таблица, которая должна быть реплицирована, должна иметь первичный ключ или, по крайней мере, уникальный ключ.
exclude_filter = (TEMP$|LOG$)%|(SYS_DB_LOG)
- exclude_without_pk
Если параметр включен, то из репликации будут исключены таблицы без первичного ключа (или уникального индекса). Если параметр выключен (по умолчанию), то при репликации таблиц без первичного ключа выдается ошибка.
exclude_without_pk = true
- log_errors
Логический параметр, определяющий как должны обрабатываться ошибки при репликации. Если значение параметра
true, то все ошибки (и предупреждения) будут записываться вreplication.log.log_errors = true
- report_errors
Логический параметр, определяющий как должны обрабатываться ошибки при репликации. Если значение параметра
true, то ошибки будут возвращаться клиентскому приложению.report_errors = false
- disable_on_error
Логический параметр, определяющий как должны обрабатываться ошибки при репликации. Если значение параметра
true, то после возникновения ошибки репликация будет прекращена.disable_on_error = false
- journal_directory (только для асинхронного режима)
Задание этого параметра включает асинхронную репликацию и говорит серверу начать создавать сегменты журнала. Данный параметр указывает на каталог для хранения файлов журнала репликации.
journal_directory = /your/db/chlog
- journal_file_prefix (только для асинхронного режима)
Префикс для имен файлов журнала репликации. Если параметр не указан, то в качестве префикса файлов журнала будет имя файла базы данных (без пути).
journal_file_prefix = warehouse_log
- journal_segment_size (только для асинхронного режима)
Максимально допустимый размер для одного сегмента репликации. Он должен быть, по крайней мере, в два раза больше размера, указанного в
buffer_size.journal_segment_size = 16777216 # 16MB
- journal_segment_count (только для асинхронного режима)
Максимально допустимое число полных сегментов репликации. После того, как предел достигнут, процесс репликации задерживается на
journal_archive_timeoutсекунд (см.ниже), чтобы догнать процесс архивирования файлов сегментов. Если какой-либо из полных сегментов не архивируется и отмечен для повторного использования в течение тайм-аута, то репликация завершается с ошибкой. Ноль означает неограниченное количество сегментов, ожидающих архивирования.journal_segment_count = 8
- journal_group_flush_delay (только для асинхронного режима)
Задержка (в миллисекундах) между коммитами для ожидания синхронной записи изменений в журнал. По умолчанию параметр принимает значение 0, то есть во время коммита происходит скидывание буфера в активный сегмент. Этот параметр задает задержку перед скидыванием буфера. Так, коммиты будут писаться в буфер до тех пор, пока он не заполнится или пока не завершится время задержки между коммитами.
journal_group_flush_delay = 30
- journal_archive_directory (только для асинхронного режима)
Данный параметр определяет директорию, куда будут архивироваться сегменты журнала. Для этого значения определена переменная
$(archivepathname)(см. ниже).journal_archive_directory = /temp/archive_logs
- journal_archive_command (только для асинхронного режима)
Программа, которая выполняется, когда некоторый сегмент репликации становится полным и нуждается в архивировании. Архивирование выполняется путем копирования сегментов из
journal_directoryвjournal_archive_directory. Сервер РЕД Базы Данных сам копирует эти сегменты. Можно задать команду архивирования самостоятельно. Эта программа должна возвращать ноль, только если архивирование успешно выполнено. Например, должен вернуться не ноль, если целевой архив уже существует.Доступны специальные предопределенные переменные:
$ (filename)- имя файла (без пути) сегмента, который нужно заархивировать;$ (pathname)- полный путь к файлу сегмента, который нужно заархивировать.Равен
journal_directory + $(filename);$ (archivepathname)- полный путь к файлу заархивированного сегмента.Равен
journal_archive_directory + $(filename).
journal_archive_command = "test ! -f $(archivepathname) && cp $(pathname) $(archivepathname)"
journal_archive_command = "copy $(pathname) $(archivepathname)"
Пользовательское архивирование позволяет использовать любую shell команду (включая скрипты / пакетные файлы) для доставки сегментов на сторону реплики. Она может использовать сжатие, FTP или что-либо еще доступное на сервере. Реальная реализация доставки зависит от администратора баз данных, РЕД База Данных просто создает сегменты на стороне ведущей базы и ожидает, что они появятся на стороне реплики.
- journal_archive_timeout (только для асинхронного режима)
Время ожидания (в секундах) заполнения активного сегмента. Если в течении этого времени не было никаких изменений в базе данных, то текущий сегмент помечается как полный и отправляется на архивацию.
Это позволяет минимизировать разрыв репликации, если база данных редко изменяется. Значение 0 означает отсутствие промежуточного архивирования, т.е. сегменты архивируются только после достижения их максимального размера (определяется
journal_segment_size).Используется только для асинхронного режима. По умолчанию значение параметра равно 60.
journal_archive_timeout = 60
- sync_replica (только для синхронного режима)
Задание этого параметра включает синхронную репликацию. Он указывает на базу данных реплики.
Значение параметра можно указывать в двух форматах. В первом варианте значение указывается одной строкой и есть ограничение на использование символа
@в имени пользователя и пароле:sync_replica = [<пользователь>:<пароль>@]<адрес сервера>:<путь к БД>
Во втором варианте
sync_replicaопределяется в виде подсекции:sync_replica = <адрес сервера>:<путь к БД> { username[_env | _file] = {<имя пользователя> | <переменная окружения> | <путь к файлу>} password[_env | _file] = {<пароль> | <переменная окружения> | <путь к файлу>} }При использовании суффикса
_envзначение будет взято из заданной переменной окружения.Если РЕД База Данных запущена как сервис, то передать переменные окружения нужно одним из следующих способов:
Задать переменную окружения в файле сервиса:
Укажите переменную окружения в секции
[Service]файлаfirebird.serviceв формате:Environment=<переменная окружения>=<значение>.Примените изменения в настройках службы командой
systemctl daemon-reload.Перезапустите сервис командой
systemctl restart firebird.
Предупреждение
После обновления СУБД настройки вернутся к значениям по умолчанию.
Задать переменную окружения в отдельном файле:
Создайте файл
/etc/systemd/system/firebird.service.d/override.conf.Укажите переменную окружения в секции
[Service]в формате:Environment=<переменная окружения>=<значение>.Примените изменения в настройках службы командой
systemctl daemon-reload.Перезапустите сервис командой
systemctl restart firebird.
Задать путь к файлу с переменными окружения в файле сервиса:
В секции
[Service]файлаfirebird.serviceопределите путь к файлу, из которого необходимо читать переменные окружения, указавEnvironmentFile=<путь к файлу>.В указанном файле задайте переменные окружения в формате
<переменная окружения>=<значение>.Примените изменения в настройках службы командой
systemctl daemon-reload.Перезапустите сервис командой
systemctl restart firebird.
При использовании суффикса
_fileзначение будет взято из первой строки определённого файла. Можно указывать как абсолютный, так и относительный путь (относительно корневого каталога инсталляции РЕД Базы Данных). Если такого файла не существует, либо файл пустой, то в лог будут записаны следующие ошибки:"<replica> specifies missing file: <...>/replicaton_pass" -- файл не найден "<replica> specifies empty file: <...>/replication_pass" -- файл пустой
В архитектурах SuperServer и SuperClassic подключение к базе данных реплики происходит при первом соединении пользователя с мастером. А отключение происходит, когда последний пользователь отсоединяется от базы данных мастера.
В архитектуре Classic каждый серверный процесс сохраняет свое собственное активное соединение с базой данных реплики.
- sync_reconnect_timeout (только для синхронного режима)
Параметр определяет таймаут (в секундах) для переподключения синхронной репликации в случае потери соединения. Если параметр не задан или указанный таймаут истёк, то в случае потери соединения либо возникнет ошибка, либо данный слейв будет исключён из репликации.
По умолчанию имеет значение 60.
sync_reconnect_timeout = 60
- auto_resync (только для адаптивного режима)
Примечание
Только для промышленной редакции.
Параметр
auto_resyncвключает использование адаптивной репликации, позволяя переключаться из синхронного режима репликации в асинхронный после потери соединения. И восстановить синхронный режим репликации после восстановления соединения.Если указано значение
true, но при этом не настроена синхронная и асинхронная репликация, то при инициализации репликации будет получено сообщение об ошибке. Также ошибка возникнет, если включить эту опцию в стандартной редакции, поскольку адаптивная репликация доступна только в промышленной версии.По умолчанию выключено (значение
false).auto_resync = false
- backoff_lag (только для адаптивного режима)
Примечание
Только для промышленной редакции. Параметр работает, только если
auto_resync = true.Целочисленный параметр, определяющий при каком отставании слейва необходимо запускать механизм возобновления синхронной репликации. Если разница между слейв-базой и мастером меньше указанного количества журналов или равна ему, то на сервере будет задержка на время, указанное в параметре
initial_backoff_delay. По умолчанию имеет значение 20.backoff_lag = 20
- initial_backoff_delay (только для адаптивного режима)
Примечание
Только для промышленной редакции. Параметр работает, только если
auto_resync = true.Время в миллисекундах, на которое будет задерживаться сервер (троттлить) для синхронизации слейв-базы с мастером. По умолчанию имеет значение 1000.
initial_backoff_delay = 1000
- backoff_factor (только для адаптивного режима)
Примечание
Только для промышленной редакции. Параметр работает, только если
auto_resync = true.Параметр определяет во сколько раз необходимо увеличить задержку сервера, если с текущим значением
initial_backoff_delayсинхронизировать реплику с мастер-базой не удалось. По умолчанию имеет значение 1.2.backoff_factor = 1.2
- max_backoff_delay (только для адаптивного режима)
Примечание
Только для промышленной редакции. Параметр работает, только если
auto_resync = true.Определяет максимальную задержку сервера в миллисекундах. По умолчанию имеет значение 30000.
max_backoff_delay = 30000
- throttle_timeout (только для адаптивного режима)
Примечание
Только для промышленной редакции. Параметр работает, только если
auto_resync = true.Таймаут (в секундах), по истечении которого троттлинг сервера будет отключён.
Если
throttle_timeout = 0(по умолчанию), троттлинг будет выполняться до синхронизации между слейв-базой и мастером.throttle_timeout = 0
Параметры настройки на слейве
- cascade_replication
Если параметр включен, то изменения, примененные к реплике, будут подлежать дальнейшей репликации (если она настроена).
cascade_replication = false
- journal_source_directory (только для асинхронного режима)
Указывает на директорию, где искать архивные журналы для применения к слейву.
journal_source_directory = /your/db/incominglog
- journal_applied_directory
Данный параметр определяет директорию, куда будут записываться примененные журналы. Если каталог не указан, то примененные журналы не будут сохраняться.
- journal_applied_count
Определяет количество примененных журналов, которое необходимо хранить. Если лимит достигнут, то старые журналы будут удаляться по мере применения новых. По умолчанию значение 0, то есть журналы не будут удаляться.
journal_applied_count = 0
- source_guid
GUID мастер-базы в формате
{XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX}, с которой идет репликация. Его можно узнать из выводаGSTAT -h.source_guid = "{6F9619FF-8B86-D011-B42D-00CF4FC964FF}"- verbose_logging
Если параметр включен, в
replication.logбудет записан подробный вывод операций, выполняемых сервером репликации. В противном случае (по умолчанию) регистрируются только ошибки и предупреждения.verbose_logging = false
- apply_idle_timeout (только для асинхронного режима)
Время ожидания (в секундах) перед сканированием новых сегментов репликации. Он используется для приостановки сервера репликации, когда все существующие сегменты уже применены к базе данных реплики, и в указанном каталоге нет новых сегментов.
apply_idle_timeout = 10
- apply_error_timeout (только для асинхронного режима)
Время ожидания (в секундах) перед повторной попыткой применения сегментов в очереди после ошибки. Он используется для приостановки сервера репликации после возникновения критической ошибки во время репликации. В этом случае сервер отключается от базы данных реплики, спит в течение указанного времени ожидания, затем снова подключается и пытается повторно применить последние сегменты с момента сбоя.
apply_error_timeout = 60
- db_copy_command
Программа (или любая
shellкоманда), которая выполняется, когда необходимо пересоздать базу данных реплики копированием мастер-базы. Такая программа должна возвращать ноль, только если копирование выполнено успешно.Доступны следующие предопределённые переменные:
$(masterdb)- строка соединения для подключения к мастер-базе;$(masteruser)- имя пользователя для подключения к мастер-базе;$(masterpwd)- пароль для подключения к мастер-базе;$(replicadb)- путь к базе данных реплики;$(replicauser)- имя пользователя для подключения к базе данных реплики;$(replicapwd)- пароль для подключения к базе данных реплики;$(guid)-GUIDмастер-базы.
Пример команды, которая делает копию базы с помощью
nbackup, устанавливает реплику и копирует базу по путиreplicadb:Пример для Windows:
db_copy_command = "del d:\db\repl.fdb && nbackup -u $(masteruser) -p $(masterpwd) -b 0 $(masterdb) d:\db\repl.fdb && nbackup -f d:\db\repl.fdb && gfix -user $(replicauser) -pas $(replicapwd) -replica $(guid) d:\db\repl.fdb && move /Y d:\db\repl.fdb $(replicadb)"
Пример для Linux:
db_copy_command = "export PATH=/opt/RedDatabase/bin:$PATH && rm -f /db/repl.fdb && nbackup -u $(masteruser) -p $(masterpwd) -b 0 $(masterdb) /db/repl.fdb && nbackup -f /db/repl.fdb && gfix –user $(replicauser) –pas $(replicapwd) -replica $(guid) /db/repl.fdb && mv -f /db/repl.fdb $(replicadb)"
- apply_tablespaces_ddl
Если параметр выключен, то связанные с табличными пространствами DDL операторы и правила внутри
CREATE TABLE,ALTER TABLE,CREATE INDEXиALTER INDEXне будут применены к базе данных реплики.apply_tablespaces_ddl = true
12.4.2. Инициализация асихронной репликации
Остановить СУБД, убедиться, что не осталось процессов сервера в системе.
Асинхронная репликация требует настройки механизма журналирования. Основным параметром является
journal_directory, который определяет местоположение журнала репликации. Как только это местоположение указано, асинхронная репликация включается, и сервер РЕД Базы Данных начинает создавать сегменты журнала.В
replication.confна мастере прописать блокdatabase = /путь/к/бд. В нем задать обязательные параметры:journal_directory— каталог с журналами репликации;journal_archive_directory— каталог с архивными журналами.
Учесть, что пользователь, от имени которого запускается СУБД, должен иметь права на запись в оба этих каталога.
Минимальная настройка будет выглядеть так:
database = /data/mydb.fdb { journal_directory = /dblogs/mydb/ journal_archive_directory = /shiplogs/mydb/ }Чтобы применить измененные настройки на мастере, все пользователи должны быть переподключены.
В самой базе данных репликация должна быть включена с помощью DDL команды:
ALTER DATABASE ENABLE PUBLICATION;
А также нужно задать таблицы, которые будут реплицироваться (набор репликации), с помощью DDL команд:
/* включение всех таблиц в репликацию, в том числе и тех, которые будут созданы в процессе */ ALTER DATABASE INCLUDE ALL TO PUBLICATION; /* включение конкретных таблиц в репликацию */ ALTER DATABASE INCLUDE TABLE T1, T2, T3 TO PUBLICATION;
Чтобы исключить таблицы из процесса репликации, выполните следующие команды:
/* исключение всех таблиц из репликации, в том числе и новых */ ALTER DATABASE EXCLUDE ALL FROM PUBLICATION; /* исключение указанных таблиц из репликации */ ALTER DATABASE EXCLUDE TABLE T1, T2, T3 FROM PUBLICATION;
Примечание
Таблицы, включенные для репликации, могут быть дополнительно отфильтрованы с помощью двух параметров в файле конфигурации:include_filterиexclude_filter. Это регулярные выражения, которые применяются к именам таблиц и определяют правила включения таблицы в набор репликации или исключения их из набора репликации.Копировать базу данных на слейв:
Заблокировать базу данных:
nbackup [-U <пользователь> -P <пароль> [-RO <роль>]] -L <база_данных>
Запустить СУБД на мастере.
Скопировать заблокированную базу данных на слейв, например, командой:
scp -c arcfour
По окончании копирования базу данных на мастере можно разблокировать:
nbackup [-U <пользователь> -P <пароль> [-RO <роль>]] -UN <база_данных>
На реплике установить СУБД РЕД База Данных.
На слейве в
replication.confпрописать блокdatabase = /путь/к/бдреплики. В нем задать обязательные параметры:journal_source_directory— каталог, в котором СУБД будет искать журналы для вливания. СУБД должна иметь на него права на запись.
Пример конфигурации выглядит так:
database = /data/mydb.fdb { journal_source_directory = /incominglogs/ }Чтобы применить измененные настройки на стороне реплики, сервер Ред Базы Данных должен быть перезапущен.
Разблокировать базу данных на слейве (копия блокированной базы данных является так же блокированной). Но не с параметром
-UN(LOCK), а с параметром-F(IXUP):nbackup -F <replica_database>
Для базы-реплики активируется режим репликации с помощью опции
-replicaутилитыGFIX:gfix -replica {read_only|read_write} <replica_database>Если реплика доступна только для чтения, то базу данных может изменять только процесс репликации. Это главным образом предназначено для обеспечения высокой доступности, поскольку база данных реплики гарантированно совпадает с мастером и может использоваться для быстрого восстановления. Обычные пользовательские соединения могут выполнять любые операции, разрешенные для транзакций только для чтения: выборку из таблиц, выполнять процедуры только для чтения, записывать в глобальные временные таблицы и т.д. Также допускается обслуживание базы данных, такое как сборка мусора, перевод базы в режим
shutdown, мониторинг.Реплики для чтения и записи позволяют одновременно в процессе репликации подключаться обычным пользователям. В этом режиме нет гарантии, что база данных реплики будет синхронизирована с мастером. Поэтому использование реплики для чтения и записи для условий высокой доступности не рекомендуется, если только пользовательские подключения на стороне реплики не ограничены изменением только таблиц, которые исключены из репликации.
Обеспечить доставку архивных журналов с мастера на слейв (например, через сетевой каталог NFS).
Запустить СУБД на слейве.
Перевести реплику в режим штатной работы можно командой:
gfix -replica none <replica_database>
Чтобы изменения настроек репликации, сделанные на мастере, вступили в силу, все пользователи должны быть повторно подключены. Чтобы изменения настроек репликации на слейве были применены, сервер нужно перезапустить.
12.4.2.1. Пример настройки асинхронной репликации
database = d:\temp\repl\master.fdb
{
journal_directory = d:\temp\repl\master_log
journal_file_prefix = repl_test
journal_segment_size = 1048576 # 1MB
journal_segment_count = 4
journal_archive_directory = d:\temp\repl \master_arch
journal_archive_command = "copy $(pathname) $(archivepathname)"
journal_archive_timeout = 0
}
database = d:\temp\repl\slave.fdb
{
journal_source_directory = d:\temp\repl\slave_log
source_guid = "{6F9619FF-8B86-D011-B42D-00CF4FC964FF}"
}
12.4.3. Инициализация синхронной репликации
Остановить СУБД на мастере, убедиться, что не осталось процессов сервера в системе.
В
replication.confпрописать блокdatabase = /путь/к/бд. В нем задать обязательный параметр подключения к реплике в виде:sync_replica = [<login>:<password>@]<database connection string>
Их может быть несколько.
В самой базе данных репликация должна быть включена с помощью DDL команды:
ALTER DATABASE ENABLE PUBLICATION;
А также нужно задать таблицы, которые будут реплицироваться (набор репликации), с помощью DDL команд:
/* включение всех таблиц в репликацию, в том числе и тех, которые будут созданы в процессе */ ALTER DATABASE INCLUDE ALL TO PUBLICATION; /* включение конкретных таблиц в репликацию */ ALTER DATABASE INCLUDE TABLE T1, T2, T3 TO PUBLICATION;
Чтобы исключить таблицы из процесса репликации, выполните следующие команды:
/* исключение всех таблиц из репликации, в том числе и новых */ ALTER DATABASE EXCLUDE ALL FROM PUBLICATION; /* исключение указанных таблиц из репликации */ ALTER DATABASE EXCLUDE TABLE T1, T2, T3 FROM PUBLICATION;
Примечание
Таблицы, включенные для репликации, могут быть дополнительно отфильтрованы с помощью двух параметров в файле конфигурации:include_filterиexclude_filter. Это регулярные выражения, которые применяются к именам таблиц и определяют правила включения таблицы в набор репликации или исключения их из набора репликации.Существует два способа инициализации реплики: из физической копии и из логической копии.
Для инициализации реплики из физической копии необходимо скопировать базу данных на слейв, например, командой:
scp -c arcfour
Для инициализации реплики из логической копии необходимо создать резервную копию базы данных:
gbak -B <база_данных-источник> <файл резервной копии>
При наличии триггеров, способных рассинхронизировать мастер и слейв (например, триггеры на отключение или подключение), нужно использовать опцию
-nodпри создании резервной копии.Далее нужно восстановить базу данных из резервной копии на стороне слейва:
gbak -C <файл резервной копии> <база_данных>
На реплике установить СУБД РЕД База Данных.
На слейве в
replication.confпрописать блокdatabase = /путь/к/бд реплики. В нем задать рекомендуемый параметрsource_guid— GUID мастер-базы.Для базы-реплики активируется режим репликации с помощью опции
–replicaутилитыGFIX:gfix -replica {read_only|read_write} <replica_database>Если реплика доступна только для чтения, то базу данных может изменять только процесс репликации. Это главным образом предназначено для обеспечения высокой доступности, поскольку база данных реплики гарантированно совпадает с мастером и может использоваться для быстрого восстановления. Обычные пользовательские соединения могут выполнять любые операции, разрешенные для транзакций только для чтения: выборку из таблиц, выполнять процедуры только для чтения, записывать в глобальные временные таблицы и т.д. Также допускается обслуживание базы данных, такое как сборка мусора, перевод базы в режим
shutdown, мониторинг.Реплики для чтения и записи позволяют одновременно в процессе репликации подключаться обычным пользователям. В этом режиме нет гарантии, что база данных реплики будет синхронизирована с мастером. Поэтому использование реплики для чтения и записи для условий высокой доступности не рекомендуется, если только пользовательские подключения на стороне реплики не ограничены изменением только таблиц, которые исключены из репликации.
Запустить СУБД на мастере.
Примечание
Перевести реплику в режим штатной работы можно командой:
gfix -replica none <replica_database>
Чтобы изменения настроек репликации, сделанные на мастере, вступили в силу, все пользователи должны быть повторно подключены. Чтобы изменения настроек репликации на слейве были применены, сервер нужно перезапустить.
12.4.3.1. Пример настройки синхронной репликации
database = d:\temp\repl\master.fdb
{
sync_replica = sysdba:masterkey@otherhost:d:\temp\repl\slave.fdb
}
12.4.4. Инициализация адаптивной репликации
Остановить СУБД на мастере, убедиться что не осталось процессов сервера в системе.
Определить местоположение журнала репликации.
В
replication.confна мастере прописать блокdatabase = /путь/к/бд. В нем задать обязательные параметры:journal_directory— каталог с журналами репликации;journal_archive_directory— каталог с архивными журналами;sync_replica- слейв-база для синхронной репликации, их может быть несколько.
Учесть, что пользователь, от имени которого запускается СУБД, должен иметь права на запись в каталоги
journal_archive_directoryиjournal_directory.Минимальная настройка будет выглядеть так:
database = /data/mydb.fdb { journal_directory = /dblogs/mydb/ journal_archive_directory = /shiplogs/mydb/ sync_replica = [<login>:<password>@]<database connection string> }Чтобы применить измененные настройки на мастере, все пользователи должны быть переподключены.
В самой базе данных репликация должна быть включена с помощью DDL команды:
ALTER DATABASE ENABLE PUBLICATION;
А также нужно задать таблицы, которые будут реплицироваться (набор репликации), с помощью DDL команд:
/* включение всех таблиц в репликацию, в том числе и тех, которые будут созданы в процессе */ ALTER DATABASE INCLUDE ALL TO PUBLICATION; /* включение конкретных таблиц в репликацию */ ALTER DATABASE INCLUDE TABLE T1, T2, T3 TO PUBLICATION;
Чтобы исключить таблицы из процесса репликации, выполните следующие команды:
/* исключение всех таблиц из репликации, в том числе и новых */ ALTER DATABASE EXCLUDE ALL FROM PUBLICATION; /* исключение указанных таблиц из репликации */ ALTER DATABASE EXCLUDE TABLE T1, T2, T3 FROM PUBLICATION;
Примечание
Таблицы, включенные для репликации, могут быть дополнительно отфильтрованы с помощью двух параметров в файле конфигурации:include_filterиexclude_filter. Это регулярные выражения, которые применяются к именам таблиц и определяют правила включения таблицы в набор репликации или исключения их из набора репликации.Существует два способа инициализации реплики: из физической копии и из логической копии.
Для инициализации реплики из физической копии необходимо скопировать базу данных на слейв, например, командой:
scp -c arcfour
Для инициализации реплики из логической копии необходимо создать резервную копию базы данных:
gbak -B <база_данных-источник> <файл резервной копии>
При наличии триггеров, способных рассинхронизировать мастер и слейв (например, триггеры на отключение или подключение), нужно использовать опцию
-nodпри создании резервной копии.Далее нужно восстановить базу данных из резервной копии на стороне слейва:
gbak -C <файл резервной копии> <база_данных>
На реплике установить СУБД РЕД База Данных.
На слейве в
replication.confпрописать блокdatabase = /путь/к/бд реплики. В нем задать обязательные параметры:source_guid— GUID мастер-базы;journal_source_directory— каталог, в котором СУБД будет искать журналы для вливания. СУБД должна иметь на него права на запись.
Пример конфигурации:
database = /data/mydb.fdb { journal_source_directory = /incominglogs/ source_guid = "{6F9619FF-8B86-D011-B42D-00CF4FC964FF}" }Для базы-реплики активируется режим репликации с помощью опции
–replicaутилитыGFIX:gfix -replica {read_only|read_write} <replica_database>Если реплика доступна только для чтения, то базу данных может изменять только процесс репликации. Это главным образом предназначено для обеспечения высокой доступности, поскольку база данных реплики гарантированно совпадает с мастером и может использоваться для быстрого восстановления. Обычные пользовательские соединения могут выполнять любые операции, разрешенные для транзакций только для чтения: выборку из таблиц, выполнять процедуры только для чтения, записывать в глобальные временные таблицы и т.д. Также допускается обслуживание базы данных, такое как сборка мусора, перевод базы в режим
shutdown, мониторинг.Реплики для чтения и записи позволяют одновременно в процессе репликации подключаться обычным пользователям. В этом режиме нет гарантии, что база данных реплики будет синхронизирована с мастером. Поэтому использование реплики для чтения и записи для условий высокой доступности не рекомендуется, если только пользовательские подключения на стороне реплики не ограничены изменением только таблиц, которые исключены из репликации.
Обеспечить доставку архивных журналов с мастера на слейв (например, через сетевой каталог NFS).
Запустить СУБД на мастере.
Перевести реплику в режим штатной работы можно командой:
gfix -replica none <replica_database>
Чтобы изменения настроек репликации, сделанные на мастере, вступили в силу, все пользователи должны быть повторно подключены. Чтобы изменения настроек репликации на слейве были применены, сервер нужно перезапустить.
12.5. Переключение на реплику
Дождитесь, когда все сегменты будут применены к реплике. На мастере они удалятся автоматически. Узнать расположение каталогов, в которых хранятся эти сегменты, можно в файле настроек репликации на мастере
/opt/RedDatabase/replication.conf.С помощью утилиты
rdbreplmgrпринудительно примените сегменты, которые не влились в реплику:/opt/RedDatabase/bin/rdbreplmgr -a /path/to/slave-db.fdb
Остановите СУБД на слейве:
systemctl stop firebird
Убедитесь, что она остановлена:
systemctl status firebird
Убедитесь, что к базе данных нет подключений:
ps -ef|grep rdbserver sudo lsof /path/to/db.fdb
Если есть подключения, то необходимо дождаться их завершения или принудительно отключить их:
sudo /opt/RedDatabase/bin/isql -u <пользователь> -p <пароль> /path/to/db.fdb delete from mon$attachments where mon$attachment_id<>current_connection; commit; select count(*) from mon$attachments; exit;
Выполните принудительное завершение всех процессов:
sudo killall rdbserver
На слейве закомментируйте настройки репликации в файле
replication.conf.В зависимости от того, как планируется использовать базу данных, выполните следующее:
Если планируется копировать реплику на другой сервер, который будет использоваться в качестве мастера, то для предотвращения возможных подключений к базе во время копирования необходимо перевести ее в режим
shutdown:sudo /opt/RedDatabase/bin/gfix -sh full -force 1 /path/to/db.fdb
После копирования разблокируйте базу на обоих серверах:
sudo /opt/RedDatabase/bin/gfix -online /path/to/db.fdb
Снимите режим репликации с базы данных на мастере:
sudo /opt/RedDatabase/bin/gfix -replica none -user <пользователь> -password <пароль> <путь до скопированной базы>
Настройте репликацию на мастере (подробнее см. раздел Пример настройки асинхронной репликации).
Если планируется использовать зеркало как мастер, то переведите слейв в состояние мастера:
sudo /opt/RedDatabase/bin/gfix -replica none -user <пользователь> -password <пароль> <путь до слейва>
Настройте параметры мастера в файле
replication.conf. Измените значение параметраServerModeв файлеfirebird.conf.
12.6. Утилиты
12.6.1. Утилита настройки журнала репликации (rdblogmgr)
Данная утилита предназначена для вывода детализации текущего состояния
журнала асинхронной репликации (общее состояние журнала, настройки асинхронной репликации, список использованных сегментов). Дополнительно,
утилита rdblogmgr позволяет выполнить ручное архивирование заданного сегмента
журнала или всех сегментов, а также принудительно помечает используемый
сегмент как полный для возможности его архивирования.
Для запуска утилиты необходимо выполнить следующую команду:
rdblogmgr -D[atabase] <имя_базы_данных> -U[ser] <имя_пользователя> -P[assword]
<пароль>
Опция |
Описание |
|---|---|
-D[atabase] <имя_базы_данных> |
Имя базы данных |
-U[ser] <имя_пользователя> |
Имя пользователя |
-P[assword] <пароль> |
Пароль пользователя |
-G[uid] <guid> |
guid базы данных |
-C[onfig] |
Показывает настройки асинхронной репликации (блок |
-S[egments] |
Показывает список используемых сегментов из каталога |
-A[rchive] <номер_сегмента> |
Архивирует отдельный сегмент журнала |
-A[rchive] all |
Архивирует все сегменты журнала |
-F[orce] |
Принудительно помечает сегмент как полный, даже если он используется. |
-Z |
Показывает версии утилиты и сервера |
-? |
Вывод доступных опций |
При каждом запуске утилиты выводится общее состояние журнала (блок Log status).
Ручное принудительное архивирование логов можно использовать, если не успевает фоновое архивирование (был сбой связи и сегменты долго не архивировались) или если база мастера вышла из строя и нужно обновить последний сегмент на слейве.
Примечание
-F [orce].Приведем пример:
rdblogmgr -D /tmp/firebird/RDB-tpcc.fdb -U sysdba -P masterkey -C -S
--------------------------------------------------------------------
Log status:
Current sequence: 2
Last modified: 2015-08-06 12:37:07
Active segment: RDB-tpcc.fdb.log-001, size: 49051
Total log size: 3483922 bytes in 2 segments
Free segments: 0, full segments: 1, archived segments: 0
Log configuration:
Log directory = /tmp/firebird/RDB-tpcc-log/
Log file prefix = RDB-tpcc.fdb
Max segment count = 0
Max segment size = 16777216
Archive directory =
Archive command =
Archive timeout = 0
Available log segments:
File name: RDB-tpcc.fdb.log-000
Sequence: 1
State: full
Size in use: 3434871 bytes
File name: RDB-tpcc.fdb.log-001
Sequence: 2
State: used
Size in use: 49051 bytes
12.6.2. Утилита для применения файлов асихронной репликации к базе (rdbreplmgr)
Утилита rdbreplmgr, ориентированная на слейв, накатывает журналы на реплику в
ручном режиме, выводит информацию о состоянии асинхронной репликации, а
также создает копию мастер-базы, если определен параметр конфигурации db_copy_command.
Для запуска утилиты необходимо выполнить следующую команду:
rdbreplmgr <команды> [<опции>] <replica_name>
Команды и опции |
Описание |
|---|---|
-C[reate] |
Создает копию мастер-базы |
-A[pply] |
Подключается к реплике и применяет журналы из каталога, указанного в |
-L[og] |
Выводит детальную информацию о журнале |
-S[tatus] |
Выводит информацию о состоянии репликации |
-U[ser] <username> |
Имя пользователя |
-P[assword] <password> |
Пароль пользователя |
-M[aster] <master> |
Путь к мастер-базе |
-G[uid] |
Ручное указание guid-мастера. |
-V[erbose] |
Подробный вывод о проверке |
-Z |
Показывает версии утилиты и сервера |
? |
Помощь |
Команда -Create выполняет программу, определенную в параметре db_copy_command, для пересоздания
слейва. Пример такой команды см. выше.
Команда -Log <путь_до_журнала> выводит информацию об операциях,
которые хранятся внутри журнала репликации. Пример выполнения команды -Log:
Report for log file <путь_до_журнала>:
Version: 1
State: arch
GUID: 478F611E-D0CC-418F-5D90-F461CAFA657A
Sequence: 5
Protocol: 2
Length: 2494
Log file segments:
Segment started at 2021-12-21 15:30:28 (1063 bytes):
StartTransaction: att_id=4585, tra_id=32432
StartSavepoint: tra_id=32432
...
Для вывода информации о журналах mc с помощью rdbreplmgr -L
необходимо в /etc/mc/mc.ext прописать следующее:
regex/.log-[0-9]3$
View=%viewascii /opt/RedDatabase/bin/rdbreplmgr -L %p
regex/.arch-[0-9]9$
View=%viewascii /opt/RedDatabase/bin/rdbreplmgr -L %p
Команда -Status выводит информацию о состоянии репликации. GUID определяется параметром source_guid в replication.conf.
Если source_guid не указан, то значение будет взято из опции -Guid утилиты rdbreplmgr.
Если опция -Guid на задана, то GUID запрашивается из мастера, заданного опцией -Master утилиты rdbreplmgr.
Если опция -Master не используется, то значение берётся из имени контрольного файла, находящегося в каталоге,
который определён параметром journal_source_directory в replication.conf. Если найдено несколько контрольных файлов,
то вызов утилиты завершится ошибкой, сообщающей о необходимости о необходимости указать GUID.
Пример выполнения команды -Status:
Status for replica d:\repl\slave_async.fdb:
Master GUID: {232822C2-9A04-498D-0C8B-971C3E0DF421}
Archive directory: d:\temp\repl\logs\
Control file: d:\temp\repl\arch\{232822C2-9A04-498D-0C8B-971C3E0DF421}
Current segment: 2
Oldest segment: absent
Active transaction: 0
Total segments in the queue: 1
12.6.3. Утилита проверки целостности данных (rdbrepldiff)
Для выполнения проверки целостности данных после репликации используется
утилита rdbrepldiff. Суть работы данной утилиты — произвести считывание всех таблиц
и всех данных в мастер-базе и слейв-базе и сверить их идентичность.
Утилиту можно запускать периодически, когда сервера слабо нагружены или
в моменты, когда есть предположения, что данные на мастере и на слейве,
в связи с какой-либо ошибкой, отличаются друг от друга и необходимо
применить какие-то меры для их синхронизации.
Для того, чтобы проверить целостность базы данных, необходимо выполнить команду:
rdbrepldiff [опции] -D[atabase] <master_name> -R[eplica] <replica_name>
Спецификация базы данных задается в формате <адрес сервера>:<путь к БД.
Опции |
Описание |
|---|---|
-U[ser] <username> |
Имя пользователя |
-P[assword] <password> |
Пароль пользователя |
-C[onfig] <config> |
Имя измененного файла конфигурации для возможности сравнивать не все сущности базы данных, а только необходимые. При этом процесс репликации не прерывается |
-M[etadata] |
Производит проверку только метаданных |
-Si[mple] |
Сравнение двух нереплицируемых баз данных |
-S[ynchronize] |
Ожидание синхронизации мастера и слейва в течение одной минуты или времени, указанного в параметре |
-N[odbtriggersoff] |
Включает ипользование триггеров при подключении к мастеру |
-T[imeout] |
Tайм-аут ожидания синхронизации (в секундах) |
-V[erbose] |
Подробный вывод о проверке |
-Z |
Показать версии утилиты и сервера |
-F |
Показать расширенный вывод о проверке. Расширенный вывод отображает:
|
-Va[lues] |
Показывает значения, которые отличаются у записей. Можно использовать только совместно с опцией |
? |
Помощь |
Для проверки должен быть указан адрес мастер-сервера и адрес слейв-сервера. После запуска утилита подключается к ним (одновременно) и выполняется чтение метаданных обеих баз. Выбирается первая таблица и идет чтение из таблицы обеих баз, сравниваются записи. Если в одной из таблиц оказалось больше данных или если данные не совпадают, то таблицы считаются не идентичными (выдается сообщение об ошибке). Этот процесс продолжается для всех остальных таблиц. Если все таблицы идентичны, то делается вывод, что базы идентичны.
При сравнении двух нереплицируемых баз данных с помощью -Simple cпецификацию базы
данных задавать не нужно. Если у сравниваемых баз отличается пользователь и/или пароль, то
необходимо передать его в формате [<логин>:<пароль>@]<путь к второй БД>. Такой расширенный
путь можно указывать ещё и для асинхронно реплицируемых баз данных.
Например:
server2:/my/replica/database.fdb
john:smith@server2:/my/replica/database.fdb
При сравнении простых баз данных сравниваются все системные таблицы, а при сравнении реплик пропускаются таблицы без уникального индекса.
Теги |
Описание |
|---|---|
-action_svc_diff |
Запуск сравнения |
-dbname |
Первая база для сравнения (должна быть локальной) |
-dif_replica |
Вторая база (реплика) |
-dif_config |
Путь к файлу конфигурации. Если не задан, то ищется в папке с базой |
-dif_metaonly |
Производит проверку только метаданных |
-dif_simple |
Сравнение двух нереплицируемых баз данных |
-dif_sync |
Ожидание синхронизации мастера и слейва в течение одной минуты или времени, указанного в параметре |
-dif_timeout |
Tайм-аут ожидания синхронизации (в секундах) |
-dif_full |
Показать расширенный вывод о проверке. Расширенный вывод отображает:
|
-dif_values |
Показывает значения, которые отличаются у записей. Можно использовать только совместно с опцией |
-verbose |
Подробный вывод о проверке |
Пример запуска rdbrepldiff через сервис:
./rdbsvcmgr localhost:service_mgr -user SYSDBA -password masterkey -action_diff
-dbname localhost:/my/other/database.fdb -dif_simple -dif_replica john:smith@/my/replica/database2.fdb